目錄
對於MySQL 5.1,MySQL AB公司引入了插件式儲存引擎體系結構,這樣,就能建立新的儲存引擎,並將它們新增到正在運行的MySQL伺服器上,而不必重新編譯伺服器本身。
該體系結構簡化了新儲存引擎的開發和部署。
本章的意圖是作為指南,用於幫助您為新的插件式儲存引擎體系結構開發儲存引擎。
關於MySQL插件式儲存引擎體系結構的更多訊息,請參見第14章:插件式儲存引擎體系結構。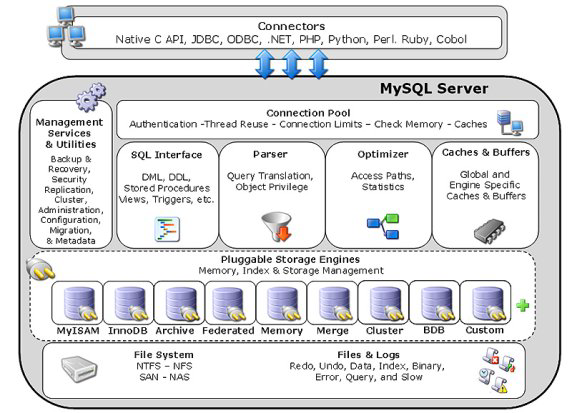
每個儲存引擎均是1個繼承類,每個類實例作為處理程式而被引用。
針對需要與特殊資料表一起工作的每個線程,處理程式是在1個處理程式的基礎上實例化的。例如,如果3個連接全都在相同的資料表上工作,需要建立3個處理程式實例。
一旦建立了處理程式實例,MySQL伺服器將向處理程式發送命令,以便執行數據儲存和檢索任務,如打開資料表、操縱行和管理索引等。
能夠以累進方式建立定制儲存引擎:開發人員能夠以只讀儲存引擎啟動,隨後新增對INSERT、UPDATE和DELETE操作的支援,甚至能夠增加對索引功能、事務和其他高級操作的支援。
16.3. 建立儲存引擎源檔案
實施新儲存引擎的最簡單方法是,通過拷貝和更改EXAMPLE儲存引擎開始。在MySQL 5.1原始碼樹的sql/examples/目錄下可找到檔案ha_example.cc和ha_example.h。關於如何獲得5.1原始碼樹的說明,請參見2.8.3節,「從開發原始碼樹安裝」。
複製檔案時,將名稱從ha_example.cc和ha_example.h更改為與儲存引擎相適應的名稱,如ha_foo.cc和ha_foo.h。
拷貝並重命名了這些檔案後,必須更換所有的EXAMPLE示範,以及具有儲存引擎名稱的示範。如果您熟悉sed,也能自動完成這些步驟:
sed s/EXAMPLE/FOO/g ha_example.h | sed s/example/foo/g ha_foo.h
sed s/EXAMPLE/FOO/g ha_example.cc | sed s/example/foo/g ha_foo.cc
handlerton(「單個處理程式」的簡稱)定義了儲存引擎,並包含指向函數的函數指針,它以整體方式作用在引擎上,而函數工作在單獨的處理程式實例中。在這類函數的一些示範中,包含用於處理註釋和回滾的事務函數。
下面給出了一個來自EXAMPLE儲存引擎的示範:
handlerton example_hton= {
"EXAMPLE",
SHOW_OPTION_YES,
"Example storage engine",
DB_TYPE_EXAMPLE_DB,
NULL, /* Initialize */
0, /* slot */
0, /* savepoint size. */
NULL, /* close_connection */
NULL, /* savepoint */
NULL, /* rollback to savepoint */
NULL, /* release savepoint */
NULL, /* commit */
NULL, /* rollback */
NULL, /* prepare */
NULL, /* recover */
NULL, /* commit_by_xid */
NULL, /* rollback_by_xid */
NULL, /* create_cursor_read_view */
NULL, /* set_cursor_read_view */
NULL, /* close_cursor_read_view */
example_create_handler, /* Create a new handler */
NULL, /* Drop a database */
NULL, /* Panic call */
NULL, /* Release temporary latches */
NULL, /* Update Statistics */
NULL, /* Start Consistent Snapshot */
NULL, /* Flush logs */
NULL, /* Show status */
NULL, /* Replication Report Sent Binlog */
HTON_CAN_RECREATE
};
下面給出了來自handler.h的handlerton定義:
typedef struct
{
const char *name;
SHOW_COMP_OPTION state;
const char *comment;
enum db_type db_type;
bool (*init)();
uint slot;
uint savepoint_offset;
int (*close_connection)(THD *thd);
int (*savepoint_set)(THD *thd, void *sv);
int (*savepoint_rollback)(THD *thd, void *sv);
int (*savepoint_release)(THD *thd, void *sv);
int (*commit)(THD *thd, bool all);
int (*rollback)(THD *thd, bool all);
int (*prepare)(THD *thd, bool all);
int (*recover)(XID *xid_list, uint len);
int (*commit_by_xid)(XID *xid);
int (*rollback_by_xid)(XID *xid);
void *(*create_cursor_read_view)();
void (*set_cursor_read_view)(void *);
void (*close_cursor_read_view)(void *);
handler *(*create)(TABLE *table);
void (*drop_database)(char* path);
int (*panic)(enum ha_panic_function flag);
int (*release_temporary_latches)(THD *thd);
int (*update_statistics)();
int (*start_consistent_snapshot)(THD *thd);
bool (*flush_logs)();
bool (*show_status)(THD *thd, stat_print_fn *print, enum ha_stat_type stat);
int (*repl_report_sent_binlog)(THD *thd, char *log_file_name, my_off_t end_offset);
uint32 flags;
} handlerton;
共有30個handlerton元素,但只有少量元素是強制性的(明確地講是前4個元素和第21個元素)。
1. 儲存引擎的名稱。這是建立資料表時將使用的名稱(CREATE TABLE ... ENGINE = FOO;)。
2. 確定使用SHOW STORAGE ENGINES命令時是否列出儲存引擎。
3. 儲存引擎註釋,對使用SHOW STORAGE ENGINES命令時顯示的儲存引擎的描述。
4. 在MySQL伺服器內唯一識別儲存引擎的整數。內置儲存引擎使用的常數定義在handler.h檔案中。作為建立常數的可選方法,可使用大於25的整數。
5. 指向儲存引擎初始化程式的指針。僅當啟動伺服器時才使用該函數,以便在實例化處理程式之前,儲存引擎類能執行必要的內務操作。
6. 插槽。保存每連接的訊息時,每個儲存引擎在thd中有自己的內存區域(實際上為指針)。它是作為thd->ha_data[foo_hton.slot]訪問的。插槽編號在使用foo_init()後由MySQL初始化。
7. 保存點偏移。為了保存每個savepoint數據,為儲存引擎提供了請求的大小(典型情況下為0)。
必須以靜態方式初始化savepoint偏移,使其具有所有的內存大小,以便保存每個savepoint的訊息。在foo_init之後,它被更改為savepoint儲存區域的偏移,儲存引擎不需要使用它。
8. 由事務性儲存引擎使用,清理其儲存段內分配的內存,和/或回滾任何未完成的事務。
9. 由事務性儲存引擎選擇性使用,建立savepoint(保存點),並將其保存到提供的內存中。
10.指向處理程式rollback_to_savepoint()函數的函數指針。它用於在事務期間返回savepoint。僅對支援保存點的儲存引擎才會填充它。
11.指向處理程式release_savepoint()函數的函數指針。它用於在事務期間釋放保存點的資源。僅對支援保存點的儲存引擎才會填充它。
12.指向處理程式commit()函數的函數指針。它用於提交事務。僅對支援事務的儲存引擎才會填充它。
13.指向處理程式rollback()函數的函數指針。它用於回滾交易。僅對支援事務的儲存引擎才會填充它。
14.XA事務性儲存引擎所需。為提交操作準備事務。將XID與事務關聯起來。
15.XA事務性儲存引擎所需。恢復由XID標識的事務。
16.XA事務性儲存引擎所需。提交由XID標識的事務。
17.XA事務性儲存引擎所需。回滾由XID標識的事務。
18.與伺服器端光標一起使用,尚未實施。
19.與伺服器端光標一起使用,尚未實施。
20.與伺服器端光標一起使用,尚未實施。
21.MANDATORY:構造並返回處理程式實例。
22.撤銷方案時,如果儲存引擎需要執行特殊步驟時使用(如在使用資料表空間的儲存引擎中使用)。
23.清理在伺服器關閉和崩潰時使用的函數。
24.InnoDB特殊函數。
25.在啟動SHOW STATUS時使用InnoDB特殊函數。
26.使用InnoDB特殊函數以開始連續讀取。
27.使用它,指明應將日誌刷新為可靠的儲存。
28.在儲存引擎上提供可被人員讀取的狀態訊息。
29.InnoDB特殊函數用於複製。
30.Handlerton標誌,通常與ALTER TABLE相關。可能的值定義於sql/handler.h檔案中,並在此列出;
31. #define HTON_NO_FLAGS 0
32. #define HTON_CLOSE_CURSORS_AT_COMMIT (1 << 0)
33. #define HTON_ALTER_NOT_SUPPORTED (1 << 1)
34. #define HTON_CAN_RECREATE (1 << 2)
35. #define HTON_FLUSH_AFTER_RENAME (1 << 3)
36. #define HTON_NOT_USER_SELECTABLE (1 << 4)
HTON_ALTER_NOT_SUPPORTED由FEDERATED儲存引擎使用,用以指明儲存引擎不接受AFTER TABLE語句。
HTON_FLUSH_AFTER_RENAME指明,重命名資料表後 ,必須使用FLUSH LOGS。
HTON_NOT_USER_SELECTABLE指明儲存引擎不能由用戶選擇,而是用作系統儲存引擎,如用於二進制日誌的偽儲存引擎。
使用儲存引擎的第1個方法是使用新的處理程式實例。
在儲存引擎源檔案中定義handlerton之前,必須定義用於函數實例化的函數題頭。下面給出了1個來自CSV引擎的示範:
static handler* tina_create_handler(TABLE *table);
正如您所見到的那樣,函數接受指向處理程式準備管理的資料表的指針,並返回處理程式對象。
定義了函數題頭後,用第21個handlerton元素中的函數指針命名函數,指明函數負責生成新的處理程式實例。
下面給出了MyISAM儲存引擎的實例化函數示範:
static handler *myisam_create_handler(TABLE *table)
{
return new ha_myisam(table);
}
該使用隨後與儲存引擎的構造程式一起工作。下面給出了來自FEDERATED儲存引擎的1個示範:
ha_federated::ha_federated(TABLE *table_arg)
:handler(&federated_hton, table_arg),
mysql(0), stored_result(0), scan_flag(0),
ref_length(sizeof(MYSQL_ROW_OFFSET)), current_position(0)
{}
下面給出了來自EXAMPLE儲存引擎的另一個示範:
ha_example::ha_example(TABLE *table_arg)
:handler(&example_hton, table_arg)
{}
FEDERATED示範中的附加元素是處理程式的額外初始化要素。所要求的最低實施是EXAMPLE示範中顯示的handler()初始化。
就給定的資料表、數據和索引,要求儲存引擎為MySQL伺服器提供儲存引擎所使用的延伸列資料表。
延伸應採用以Null終結的字串數組形式。下面給出了CSV引擎使用的數組:
static const char *ha_tina_exts[] = {
".CSV",
NullS
};
使用bas_ext()函數時返回該數組。
const char **ha_tina::bas_ext() const
{
return ha_tina_exts;
}
通過提供延伸訊息,您還能忽略DROP TABLE功能的實施,這是因為,通過關閉資料表並用您指定的延伸刪除所有檔案,MySQL伺服器能實現該功能。
一旦實例化了處理程式,所需的第1個操作很可能是建立資料表。
您的儲存引擎必須實現create()虛擬函數:
virtual int create(const char *name, TABLE *form, HA_CREATE_INFO *info)=0;
該函數應建立所有必須的檔案,然後關閉資料表。MySQL伺服器將使用隨後需打開的資料表。
*name參數是資料表的名稱。*form參數是st_table結構,該結構定義了資料表並與MySQL伺服器已建立的tablename.frm檔案的內容匹配。在大多數情況下,儲存引擎不需要更改tablename.frm檔案,也沒有支援該操作的預置功能。
*info參數是包含CREATE TABLE語句用於建立資料表所需訊息的結構。該結構定義於handler.h檔案中,並為了便於參考列於下面:
typedef struct st_ha_create_information
{
CHARSET_INFO *table_charset, *default_table_charset;
LEX_STRING connect_string;
const char *comment,*password;
const char *data_file_name, *index_file_name;
const char *alias;
ulonglong max_rows,min_rows;
ulonglong auto_increment_value;
ulong table_options;
ulong avg_row_length;
ulong raid_chunksize;
ulong used_fields;
SQL_LIST merge_list;
enum db_type db_type;
enum row_type row_type;
uint null_bits; /* NULL bits at start of record */
uint options; /* OR of HA_CREATE_ options */
uint raid_type,raid_chunks;
uint merge_insert_method;
uint extra_size; /* length of extra data segment */
bool table_existed; /* 1 in create if table existed */
bool frm_only; /* 1 if no ha_create_table() */
bool varchar; /* 1 if table has a VARCHAR */
} HA_CREATE_INFO;
基本的儲存引擎能忽略*form和*info的內容,這是因為,真正所需的是建立儲存引擎所使用的數據檔案,以及對數據檔案的可能初始化操作(假定儲存檔案是基於檔案的)。
下面給出了來自CSV儲存引擎的實施示範:
int ha_tina::create(const char *name, TABLE *table_arg,
HA_CREATE_INFO *create_info)
{
char name_buff[FN_REFLEN];
File create_file;
DBUG_ENTER("ha_tina::create");
if ((create_file= my_create(fn_format(name_buff, name, "", ".CSV",
MY_REPLACE_EXT|MY_UNPACK_FILENAME),0,
O_RDWR | O_TRUNC,MYF(MY_WME))) < 0)
DBUG_RETURN(-1);
my_close(create_file,MYF(0));
DBUG_RETURN(0);
}
在前面的例子中,CSV引擎未引用*table_arg或*create_info參數,而是簡單地建立了所需的數據檔案,關閉它們,並返回。
my_create和my_close函數是定義於src/include/my_sys.h檔案中的助手函數。
在資料表上執行任何讀或寫操作之前,MySQL伺服器將使用open()方法打開資料表數據和索引檔案(如果存在的話)。
int open(const char *name, int mode, int test_if_locked);
第1個參數是要打開的資料表的名稱。第2個參數確定了要打開的檔案或準備執行的操作。它們的值定義於handler.h中,並為了方便起見列在下面:
#define HA_OPEN_KEYFILE 1
#define HA_OPEN_RNDFILE 2
#define HA_GET_INDEX 4
#define HA_GET_INFO 8 /* do a ha_info() after open */
#define HA_READ_ONLY 16 /* File opened as readonly */
#define HA_TRY_READ_ONLY 32 /* Try readonly if can't open with read and write */
#define HA_WAIT_IF_LOCKED 64 /* Wait if locked on open */
#define HA_ABORT_IF_LOCKED 128 /* skip if locked on open.*/
#define HA_BLOCK_LOCK 256 /* unlock when reading some records */
#define HA_OPEN_TEMPORARY 512
最後一個選項規定了是否要在打開資料表之前檢查資料表上的鎖定。
在典型情況下,儲存引擎需要實施某種形式的共享訪問控制,以防止在多線程環境下的檔案損壞。關於如何實施檔案鎖定的示範,請參見sql/examples/ha_tina.cc的get_share()和free_share()方法。
最基本的儲存引擎能實現只讀資料表掃瞄功能。這類引擎可用於支援SQL日誌查詢、以及在MySQL之外填充的其他數據檔案。
本節介紹的方法實施提供了建立更高級儲存引擎的基礎。
下面給出了在CSV引擎的9行資料表掃瞄過程中進行的方法使用:
ha_tina::store_lock ha_tina::external_lock ha_tina::info ha_tina::rnd_init ha_tina::extra - ENUM HA_EXTRA_CACHE Cache record in HA_rrnd() ha_tina::rnd_next ha_tina::rnd_next ha_tina::rnd_next ha_tina::rnd_next ha_tina::rnd_next ha_tina::rnd_next ha_tina::rnd_next ha_tina::rnd_next ha_tina::rnd_next ha_tina::extra - ENUM HA_EXTRA_NO_CACHE End cacheing of records (def) ha_tina::external_lock ha_tina::extra - ENUM HA_EXTRA_RESET Reset database to after open
在執行任何讀取或寫操作之前,使用store_lock()函數。
將鎖定新增到資料表鎖定處理程式之前(請參見thr_lock.c),mysqld將用請求的鎖使用儲存鎖定。目前,儲存鎖定能將寫鎖定更改為讀鎖定(或其他鎖定),忽略鎖定(如果不打算使用MySQL鎖定的話),或為很多資料表新增鎖定(就像使用MERGE處理程式時作的那樣)。
例如,Berkeley DB能將所有的WRITE鎖定更改為TL_WRITE_ALLOW_WRITE(資料表示我們正在執行WRITES,但我們仍允許其他人員進行操作)。
釋放鎖定時,也將使用store_lock(),在這種情況下,通常不需做任何事。
在某些特殊情況下,MySQL可能會發送對TL_IGNORE的請求。這意味著我們正在請求與上次相同的鎖定,這也應被忽略(當我們打開了資料表的某一部分時,如果其他人執行了資料表刷新操作,就會出現該情況,此時,mysqld將關閉並再次打開資料表,然後獲取與上次相同的鎖定)。我們打算在將來刪除該特性。
可能的鎖定類型定義於includes/thr_lock.h中,並列在下面:
enum thr_lock_type
{
TL_IGNORE=-1,
TL_UNLOCK, /* UNLOCK ANY LOCK */
TL_READ, /* Read lock */
TL_READ_WITH_SHARED_LOCKS,
TL_READ_HIGH_PRIORITY, /* High prior. than TL_WRITE. Allow concurrent insert */
TL_READ_NO_INSERT, /* READ, Don't allow concurrent insert */
TL_WRITE_ALLOW_WRITE, /* Write lock, but allow other threads to read / write. */
TL_WRITE_ALLOW_READ, /* Write lock, but allow other threads to read / write. */
TL_WRITE_CONCURRENT_INSERT, /* WRITE lock used by concurrent insert. */
TL_WRITE_DELAYED, /* Write used by INSERT DELAYED. Allows READ locks */
TL_WRITE_LOW_PRIORITY, /* WRITE lock that has lower priority than TL_READ */
TL_WRITE, /* Normal WRITE lock */
TL_WRITE_ONLY /* Abort new lock request with an error */
};
實際的鎖定處理因鎖定實施的不同而不同,您可以選擇某些請求的鎖定類型或不選擇任何鎖定類型,並根據情況恰當地代入您自己的方法。下面給出了1個CSV儲存引擎實施示範:
THR_LOCK_DATA **ha_tina::store_lock(THD *thd,
THR_LOCK_DATA **to,
enum thr_lock_type lock_type)
{
if (lock_type != TL_IGNORE && lock.type == TL_UNLOCK)
lock.type=lock_type;
*to++= &lock;
return to;
}
external_lock()函數是在事務開始時使用的,或發出LOCK TABLES語句時使用的,用於事務性儲存引擎。
在sql/ha_innodb.cc和sql/ha_berkeley.cc檔案中,可找到使用external_lock()的示範,但大多數儲存引擎簡單地返回0,就像EXAMPLE儲存引擎那樣:
int ha_example::external_lock(THD *thd, int lock_type)
{
DBUG_ENTER("ha_example::external_lock");
DBUG_RETURN(0);
}
在任何資料表掃瞄之前使用的函數是rnd_init()函數。函數rnd_init()用於為資料表掃瞄作準備,將計數器和指針復位為資料表的開始狀態。
下述示範來自CSV儲存引擎:
int ha_tina::rnd_init(bool scan)
{
DBUG_ENTER("ha_tina::rnd_init");
current_position= next_position= 0;
records= 0;
chain_ptr= chain;
DBUG_RETURN(0);
}
最佳化程式所需的訊息不是通過返回值給定的,您需填充儲存引擎類的特定屬性,當info()使用返回後,最佳化程式將讀取儲存引擎類。
除了供最佳化程式使用外,在使用info()函數期間,很多值集合還將用於SHOW TABLE STATUS語句。
在sql/handler.h中列出了完整的公共屬性,下面給出了一些常見的屬性:
ulonglong data_file_length; /* Length off data file */
ulonglong max_data_file_length; /* Length off data file */
ulonglong index_file_length;
ulonglong max_index_file_length;
ulonglong delete_length; /* Free bytes */
ulonglong auto_increment_value;
ha_rows records; /* Records in table */
ha_rows deleted; /* Deleted records */
ulong raid_chunksize;
ulong mean_rec_length; /* physical reclength */
time_t create_time; /* When table was created */
time_t check_time;
time_t update_time;
對於資料表掃瞄,最重要的屬性是「records」,它指明了資料表中的記錄數。當儲存引擎指明資料表中有0或1行時,或有2行以上時,在這兩種情況下,最佳化程式的執行方式不同。因此,當您在執行資料表掃瞄之前不清楚資料表中有多少行時,應返回大於等於2的值,這很重要(例如,數據是在外部填充的)。
16.9.5. 實施extra()函數
執行某些操作之前,應使用extra()函數,以便為儲存引擎就如何執行特定操作予以提示。
額外使用中的提示實施不是強制性的,大多數儲存引擎均返回0:
int ha_tina::extra(enum ha_extra_function operation)
{
DBUG_ENTER("ha_tina::extra");
DBUG_RETURN(0);
}
完成資料表的初始化操作後,MySQL伺服器將使用處理程式的rnd_next()函數,每兩個掃瞄行使用1次,直至滿足了伺服器的搜索條件或到達檔案結尾為止,在後一種情況下,處理程式將返回HA_ERR_END_OF_FILE。
rnd_next()函數有一個名為*buf的單字節數組參數。對於*buf參數,必須按內部MySQL格式用資料表行的內容填充它。
伺服器採用了三種數據格式:固定長度行,可變長度行,以及具有BLOB指針的可變長度行。對於每種格式,各列將按照它們由CREATE TABLE語句定義的順序顯示(資料表定義保存在.frm檔案中,最佳化程式和處理程式均能從相同的源,即TABLE結構,訪問資料表的元數據)。
每種格式以每列1比特的"NULL bitmap"開始。對於含6個列的資料表,其bitmap為1字節,對於含9~16列的資料表,其bitmap為2字節,依此類推。要想指明特定的值是NULL,應將該列NULL位設置為1。
當NULL bitmap逐個進入列後,每列將具有MySQL手冊的「MySQL數據類型」一節中指定的大小。在伺服器中,列的數據類型定義在sql/field.cc檔案中。對於固定長度行格式,列將簡單地逐個放置。對於可變長度行,VARCHAR列將被編碼為1字節長,後跟字串。對於具有BLOB列的可變長度行,每個blob由兩部分資料表示:首先是資料表示BLOB實際大小的整數,然後是指向內存中BLOB的指針。
在任何資料表處理程式中從rnd_next()開始,可找到行轉換(或「包裝」)的示範。例如,在ha_tina.cc中,find_current_row()內的代碼給出了使用TABLE結構(由資料表指向的)和字串對像(命名緩衝)包裝字元數據(來自CSV檔案)的方法。將行寫回磁盤需要反向轉換,從內部格式解包。
下述示範來自CSV儲存引擎:
int ha_tina::rnd_next(byte *buf)
{
DBUG_ENTER("ha_tina::rnd_next");
statistic_increment(table->in_use->status_var.ha_read_rnd_next_count, &LOCK_status);
current_position= next_position;
if (!share->mapped_file)
DBUG_RETURN(HA_ERR_END_OF_FILE);
if (HA_ERR_END_OF_FILE == find_current_row(buf) )
DBUG_RETURN(HA_ERR_END_OF_FILE);
records++;
DBUG_RETURN(0);
}
對於從內部行格式到CSV行格式的轉換,它是在find_current_row()函數中執行的。
int ha_tina::find_current_row(byte *buf)
{
byte *mapped_ptr= (byte *)share->mapped_file + current_position;
byte *end_ptr;
DBUG_ENTER("ha_tina::find_current_row");
/* EOF should be counted as new line */
if ((end_ptr= find_eoln(share->mapped_file, current_position,
share->file_stat.st_size)) == 0)
DBUG_RETURN(HA_ERR_END_OF_FILE);
for (Field **field=table->field ; *field ; field++)
{
buffer.length(0);
mapped_ptr++; // Increment past the first quote
for(;mapped_ptr != end_ptr; mapped_ptr++)
{
// Need to convert line feeds!
if (*mapped_ptr == '"' &&
(((mapped_ptr[1] == ',') && (mapped_ptr[2] == '"')) ||
(mapped_ptr == end_ptr -1 )))
{
mapped_ptr += 2; // Move past the , and the "
break;
}
if (*mapped_ptr == '\\' && mapped_ptr != (end_ptr - 1))
{
mapped_ptr++;
if (*mapped_ptr == 'r')
buffer.append('\r');
else if (*mapped_ptr == 'n' )
buffer.append('\n');
else if ((*mapped_ptr == '\\') || (*mapped_ptr == '"'))
buffer.append(*mapped_ptr);
else /* This could only happed with an externally created file */
{
buffer.append('\\');
buffer.append(*mapped_ptr);
}
}
else
buffer.append(*mapped_ptr);
}
(*field)->store(buffer.ptr(), buffer.length(), system_charset_info);
}
next_position= (end_ptr - share->mapped_file)+1;
/* Maybe use \N for null? */
memset(buf, 0, table->s->null_bytes); /* We do not implement nulls! */
DBUG_RETURN(0);
}
對於使用共享訪問方法的儲存引擎(如CSV引擎和其他示範引擎中顯示的方法),必須將它們自己從共享結構中刪除:
int ha_tina::close(void)
{
DBUG_ENTER("ha_tina::close");
DBUG_RETURN(free_share(share));
}
對於使用其自己共享管理系統的儲存引擎,應使用任何所需的方法,在它們的處理程式中,從已打開資料表的共享區刪除處理程式實例。
16.11. 為儲存引擎新增對INSERT的支援
所有的INSERT操作均是通過write_row()函數予以處理的:
int ha_foo::write_row(byte *buf)
*buf參數包含將要插入的行,採用內部MySQL格式。基本的儲存引擎將簡單地前進到數據檔案末尾,並直接在末尾處新增緩衝的內容,這樣就能使行讀取變得簡單,這是因為,您可以讀取行並將其直接傳遞到rnd_next()函數的緩衝參數中。
寫入行的程序與讀取行的程序相反:從MySQL內部行格式獲取數據,並將其寫入數據檔案。下述示範來自CSV儲存引擎:
int ha_tina::write_row(byte * buf)
{
int size;
DBUG_ENTER("ha_tina::write_row");
statistic_increment(table->in_use->status_var.ha_write_count, &LOCK_status);
if (table->timestamp_field_type & TIMESTAMP_AUTO_SET_ON_INSERT)
table->timestamp_field->set_time();
size= encode_quote(buf);
if (my_write(share->data_file, buffer.ptr(), size, MYF(MY_WME | MY_NABP)))
DBUG_RETURN(-1);
if (get_mmap(share, 0) > 0)
DBUG_RETURN(-1);
DBUG_RETURN(0);
}
前述示範中的兩條註釋包括,更新關於寫入操作的資料表統計,以及在寫入行之前設置時間戳。
16.12. 為儲存引擎新增對UPDATE的支援
通過執行資料表掃瞄操作,在找到與UPDATE語句的WHERE子句匹配的行後,MySQL伺服器將執行UPDATE語句,然後使用update_row()函數:
int ha_foo::update_row(const byte *old_data, byte *new_data)
*old_data參數包含更新前位於行中的數據,而*new_data參數包含行的新內容(採用MySQL內部行格式)。
更新的執行取決於行格式和儲存實施方式。某些儲存引擎將替換恰當位置的數據,而其他實施方案則會刪除已有的行,並在數據檔案末尾新增新行。
非事務性儲存引擎通常會忽略*old_data參數的內容,僅處理*new_data緩衝。事務性儲存引擎可能需要比較緩衝,以確定在上次回滾中出現了什麼變化。
如果正在更新的資料表中包含時間戳列,對時間戳的更新將由update_row()使用管理。下述示範來自CSV引擎:
int ha_tina::update_row(const byte * old_data, byte * new_data)
{
int size;
DBUG_ENTER("ha_tina::update_row");
statistic_increment(table->in_use->status_var.ha_read_rnd_next_count,
&LOCK_status);
if (table->timestamp_field_type & TIMESTAMP_AUTO_SET_ON_UPDATE)
table->timestamp_field->set_time();
size= encode_quote(new_data);
if (chain_append())
DBUG_RETURN(-1);
if (my_write(share->data_file, buffer.ptr(), size, MYF(MY_WME | MY_NABP)))
DBUG_RETURN(-1);
DBUG_RETURN(0);
}
請注意上例中的時間戳設置。
MySQL伺服器採用了與INSERT語句相同的方法來執行DELETE語句:伺服器使用rnd_next()函數跳到要刪除的行,然後使用delete_row()函數刪除行。
int ha_foo::delete_row(const byte *buf)
*buf參數包含要刪除行的內容。對於大多數儲存引擎,該參數可被忽略,但事務性儲存引擎可能需要保存刪除的數據,以供回滾操作使用。
下述示範來自CSV儲存引擎:
int ha_tina::delete_row(const byte * buf)
{
DBUG_ENTER("ha_tina::delete_row");
statistic_increment(table->in_use->status_var.ha_delete_count,
&LOCK_status);
if (chain_append())
DBUG_RETURN(-1);
--records;
DBUG_RETURN(0);
}
前述示範的步驟是更新delete_count統計,並記錄計數。
目的
定義儲存引擎所使用的檔案延伸。
概要
| virtual const char ** bas_ext ( | ); |
| ; |
描述
這是bas_ext方法。使用它,可為MySQL伺服器提供儲存引擎所使用的檔案延伸列資料表。該列資料表將返回以Null終結的字串數組。
通過提供延伸列資料表,在很多情況下,儲存引擎能省略delete_table()函數,這是因為MySQL伺服器將關閉所有對資料表的引用,並使用指定的延伸刪除所有檔案。
參數
該函數無參數。
返回值
返回值是儲存引擎延伸的以Null終結的字串數組。下面給出了CSV引擎的示範:
static const char *ha_tina_exts[] = { ".CSV", NullS };
用法
static const char *ha_tina_exts[] =
{
".CSV",
NullS
};
const char **ha_tina::bas_ext() const
{
return ha_tina_exts;
}
預設實施
static const char *ha_example_exts[] = {
NullS
};
const char **ha_example::bas_ext() const
{
return ha_example_exts;
}
目的
關閉打開的資料表。
概要
| virtual int close ( | void); |
| void ; |
描述
這是close方法。
關閉資料表。這是釋放任何已分配資源的恰當時機。
從sql_base.cc、sql_select.cc和table.cc使用它。在sql_select.cc中,它僅用於關閉臨時資料表,或在將臨時資料表轉換為myisam資料表的過程中關閉資料表。關於sql_base.cc,請查看close_data_tables()。
參數
void
返回值
無返回值。
用法
取自CSV引擎的示範:
int ha_example::close(void)
{
DBUG_ENTER("ha_example::close");
DBUG_RETURN(free_share(share));
}
目的
建立新資料表。
概要
| virtual int create ( | name, | |
| form, | ||
| info); |
| const char * | name ; |
| TABLE * | form ; |
| HA_CREATE_INFO * | info ; |
描述
這是create方法。
使用create()以建立資料表。變數名稱為資料表的名稱。使用create()時,不需要打開資料表。此外,由於已建立了.frm檔案,不推薦調整create_info。
由ha_create_table()從handle.cc中使用。
參數
name
form
info
返回值
無返回值。
用法
CSV搜索引擎示範:
int ha_tina::create(const char *name, TABLE *table_arg,
HA_CREATE_INFO *create_info)
{
char name_buff[FN_REFLEN];
File create_file;
DBUG_ENTER("ha_tina::create");
if ((create_file= my_create(fn_format(name_buff, name, "", ".CSV",
MY_REPLACE_EXT|MY_UNPACK_FILENAME),0,
O_RDWR | O_TRUNC,MYF(MY_WME))) < 0)
DBUG_RETURN(-1);
my_close(create_file,MYF(0));
DBUG_RETURN(0);
}
目的
刪除行。
概要
| virtual int delete_row ( | buf); |
| const byte * | buf ; |
描述
這是delete_row方法。
Buf包含刪除行的副本。使用了當前行後,伺服器將立刻使用它(通過前一個rnd_next()或索引使用)。如果存在指向上一行的指針,或能夠訪問 主鍵,刪除操作將更為容易。請記住,伺服器不保證連續刪除。可以使用ORDER BY子句。
在sql_acl.cc和sql_udf.cc中使用,以管理內部的資料表訊息。在sql_delete.cc、sql_insert.cc和sql_select.cc中使用。在sql_select中,它用於刪除副本,而在插入操作中,它用於REPLACE使用。
參數
buf
返回值
無返回值。
用法
預設實施
{ return HA_ERR_WRONG_COMMAND; }
目的
用來自bas_ext()的延伸刪除所有檔案。
概要
| virtual int delete_table ( | name); |
| const char * | name ; |
描述
這是delete_table方法。
用於刪除資料表。使用delete_table()時,所有已打開的對該資料表的引用均將被關閉(並釋放全局共享的引用)。變數名稱為資料表名。此時,需要刪除任何已建立的檔案。
如果未實施它,將從handler.cc使用預設的delete_table(),並用bas_ext()返回的檔案延伸刪除所有檔案。假定處理程式返回的延伸比檔案實際使用的多。
由delete_table和ha_create_table()從handler.cc使用。如果為儲存引擎指定了table_flag HA_DROP_BEFORE_CREATE,僅在建立過程中使用。
參數
name: 資料表的基本名稱
返回值
· 如果成功地從base_ext刪除了至少1個檔案而且未出現除ENOENT之外的錯誤,返回0。
· #: Error
用法
目的
為事務處理資料表鎖定。
概要
| virtual int external_lock ( | thd, | |
| lock_type); |
| THD * | thd ; |
| int | lock_type ; |
描述
這是external_lock方法。
在lock.cc中「用於mysql的鎖定函數」一節,給出了關於該議題的額外註釋,值的一讀。
在資料表上建立鎖定。如果實施了能處理事務的儲存引擎,請查看ha_berkely.cc,以瞭解如何執行該操作的方法。否則,應考慮在此使用flock()。
由lock_external()和unlock_external()從lock.cc中使用。也能由copy_data_between_tables()從sql_table.cc中使用。
參數
thd
lock_type
返回值
無返回值。
預設實施
{ return 0; }
目的
將提示從伺服器傳遞給儲存引擎。
概要
| virtual int extra ( | operation); |
| enum ha_extra_function | operation ; |
描述
這是extra方法。
無論何時,當伺服器希望將提示發送到儲存引擎時,將使用extra()。MyISAM引擎實現了大多數提示。ha_innodb.cc給出了最詳盡的提示列資料表。
參數
operation
返回值
無返回值。
用法
預設實施
預設情況下,儲存引擎傾向於不實施任何提示。
{ return 0; }
目的
提示儲存引擎通報統計訊息。
概要
| virtual void info ( | uint); |
| uint ; |
描述
這是info方法。
::info()用於將訊息返回給最佳化程式。目前,該資料表處理程式未實施實際需要的大多數字段。SHOW也能利用該數據。注意,或許您打算在您的代碼中包含下述內容「if (records > 2) records = 2」。原因在於,伺服器僅最佳化具有一條記錄的情形。如果在資料表掃瞄過程中,您不清楚記錄的數目,最好將記錄數設為2,以便能夠返回盡可能多的所需記錄。除了記錄外,您或許還希望設置其他變數,包括:刪除的記錄,data_file_length,index_file_length,delete_length,check_time。更多訊息,請參見handler.h中的公共變數。
在下述檔案中使用:filesort.cc ha_heap.cc item_sum.cc opt_sum.cc sql_delete.cc sql_delete.cc sql_derived.cc sql_select.cc sql_select.cc sql_select.cc sql_select.cc sql_select.cc sql_show.cc sql_show.cc sql_show.cc sql_show.cc sql_table.cc sql_union.cc sql_update.cc
參數
uint
返回值
無返回值。
用法
該示範取自CSV儲存引擎:
void ha_tina::info(uint flag)
{
DBUG_ENTER("ha_tina::info");
/* This is a lie, but you don't want the optimizer to see zero or 1 */
if (records < 2)
records= 2;
DBUG_VOID_RETURN;
}
目的
打開資料表。
概要
| virtual int open ( | name, | |
| mode, | ||
| test_if_locked); |
| const char * | name ; |
| int | mode ; |
| uint | test_if_locked ; |
描述
這是open方法。
用於打開資料表。名稱是檔案的名稱。在需要打開資料表時打開它。例如,當請求在資料表上執行選擇操作時(對於每一請求,資料表未打開並被關閉,對其進行高速緩衝處理)。
由handler::ha_open()從handler.cc中使用。通過使用ha_open(),然後使用處理程式相關的open(),伺服器打開所有資料表。
對於處理程式對象,將作為初始化的一部分並在將其用於正常查詢之前打開它(並非總在元數據變化之前)。如果打開了對象,在刪除之前還將關閉它。
這是open方法。使用open以打開資料庫資料表。
第1個參數是要打開的資料表的名稱。第2個參數決定了要打開的檔案或將要執行的操作。這類值定義於handler.h中,為了方便起見在此列出:
#define HA_OPEN_KEYFILE 1
#define HA_OPEN_RNDFILE 2
#define HA_GET_INDEX 4
#define HA_GET_INFO 8 /* do a ha_info() after open */
#define HA_READ_ONLY 16 /* File opened as readonly */
#define HA_TRY_READ_ONLY 32 /* Try readonly if can't open with read and write */
#define HA_WAIT_IF_LOCKED 64 /* Wait if locked on open */
#define HA_ABORT_IF_LOCKED 128 /* skip if locked on open.*/
#define HA_BLOCK_LOCK 256 /* unlock when reading some records */
#define HA_OPEN_TEMPORARY 512
最後的選項規定了在打開資料表之前是否應檢查資料表上的鎖定。
典型情況下,儲存引擎需要實現某種形式的共享訪問控制,以防止多線程環境下的檔案損壞。關於如何實現檔案鎖定的示範,請參見sql/examples/ha_tina.cc的get_share()和free_share()方法。
參數
name
mode
test_if_locked
返回值
無返回值。
用法
該示範取自CSV儲存引擎:
int ha_tina::open(const char *name, int mode, uint test_if_locked)
{
DBUG_ENTER("ha_tina::open");
if (!(share= get_share(name, table)))
DBUG_RETURN(1);
thr_lock_data_init(&share->lock,&lock,NULL);
ref_length=sizeof(off_t);
DBUG_RETURN(0);
}
目的
為資料表掃瞄功能初始化處理程式。
概要
| virtual int rnd_init ( | scan); |
| bool | scan ; |
描述
這是rnd_init方法。
當系統希望儲存引擎執行資料表掃瞄時,將使用rnd_init()。
與index_init()不同,rnd_init()可以使用兩次,兩次使用之間不使用rnd_end()(僅當scan=1時才有意義)。隨後,第2次使用應準備好新的資料表掃瞄。例如,如果rnd_init分配了光標,第2次使用應將光標定位於資料表的開始部分,不需要撤銷分配並再次分配。
從下述檔案使用:filesort.cc, records.cc, sql_handler.cc, sql_select.cc, sql_table.cc, 和sql_update.cc。
參數
scan
返回值
無返回值。
用法
該示範取自CSV儲存引擎:
int ha_tina::rnd_init(bool scan)
{
DBUG_ENTER("ha_tina::rnd_init");
current_position= next_position= 0;
records= 0;
chain_ptr= chain;
DBUG_RETURN(0);
}
目的
從資料表中讀取下一行,並將其返回伺服器。
概要
| virtual int rnd_next ( | buf); |
| byte * | buf ; |
描述
這是rnd_next方法。
對於資料表掃瞄的每一行使用它。耗盡記錄時,應返回HA_ERR_END_OF_FILE。用行訊息填充buff。資料表的字段結構是以伺服器能理解的方式將數據保存到buf中的鍵。
從下述檔案使用:filesort.cc, records.cc, sql_handler.cc, sql_select.cc, sql_table.cc, 和sql_update.cc。
參數
buf
返回值
無返回值。
用法
下述示範取自ARCHIVE儲存引擎:
int ha_archive::rnd_next(byte *buf)
{
int rc;
DBUG_ENTER("ha_archive::rnd_next");
if (share->crashed)
DBUG_RETURN(HA_ERR_CRASHED_ON_USAGE);
if (!scan_rows)
DBUG_RETURN(HA_ERR_END_OF_FILE);
scan_rows--;
statistic_increment(table->in_use->status_var.ha_read_rnd_next_count,
&LOCK_status);
current_position= gztell(archive);
rc= get_row(archive, buf);
if (rc != HA_ERR_END_OF_FILE)
records++;
DBUG_RETURN(rc);
}
目的
建立和釋放資料表鎖定。
概要
| virtual THR_LOCK_DATA ** store_lock ( | thd, | |
| to, | ||
| lock_type); |
| THD * | thd ; |
| THR_LOCK_DATA ** | to ; |
| enum thr_lock_type | lock_type ; |
描述
這是store_lock方法。
下面介紹了關於handler::store_lock()的概念:
該語句決定了在資料表上需要何種鎖定。對於updates/deletes/inserts,我們得到WRITE鎖定;對於SELECT...,我們得到讀鎖定。
將鎖定新增到資料表鎖定處理程式之前(請參見thr_lock.c),mysqld將用請求的鎖定使用儲存鎖定。目前,儲存鎖定能將寫鎖定更改為讀鎖定(或某些其他鎖定),忽略鎖定(如果不打算使用MySQL資料表鎖定),或為很多資料表新增鎖定(就像使用MERGE處理程式時那樣)。
例如,Berkeley DB能夠將所有的WRITE鎖定更改為TL_WRITE_ALLOW_WRITE(表明正在執行WRITES操作,但我們仍允許其他人執行操作)。
釋放鎖定時,也將使用store_lock()。在這種情況下,通常不需要作任何事。
在某些特殊情況下,MySQL可能會發送對TL_IGNORE的請求。這意味著我們正在請求與上次相同的鎖定,這也應被忽略(當我們打開了資料表的某一部分時,如果其他人執行了資料表刷新操作,就會出現該情況,此時,mysqld將關閉並再次打開資料表,然後獲取與上次相同的鎖定)。我們打算在將來刪除該特性。
由get_lock_data()從lock.cc中使用。
參數
thd
to
lock_type
返回值
無返回值。
用法
下述示範取自ARCHIVE儲存引擎:
/*
Below is an example of how to setup row level locking.
*/
THR_LOCK_DATA **ha_archive::store_lock(THD *thd,
THR_LOCK_DATA **to,
enum thr_lock_type lock_type)
{
if (lock_type == TL_WRITE_DELAYED)
delayed_insert= TRUE;
else
delayed_insert= FALSE;
if (lock_type != TL_IGNORE && lock.type == TL_UNLOCK)
{
/*
Here is where we get into the guts of a row level lock.
If TL_UNLOCK is set
If we are not doing a LOCK TABLE or DISCARD/IMPORT
TABLESPACE, then allow multiple writers
*/
if ((lock_type >= TL_WRITE_CONCURRENT_INSERT &&
lock_type <= TL_WRITE) && !thd->in_lock_tables
&& !thd->tablespace_op)
lock_type = TL_WRITE_ALLOW_WRITE;
/*
In queries of type INSERT INTO t1 SELECT ... FROM t2 ...
MySQL would use the lock TL_READ_NO_INSERT on t2, and that
would conflict with TL_WRITE_ALLOW_WRITE, blocking all inserts
to t2. Convert the lock to a normal read lock to allow
concurrent inserts to t2.
*/
if (lock_type == TL_READ_NO_INSERT && !thd->in_lock_tables)
lock_type = TL_READ;
lock.type=lock_type;
}
*to++= &lock;
return to;
}
目的
更新已有行的內容。
概要
| virtual int update_row ( | old_data, | |
| new_data); |
| const byte * | old_data ; |
| byte * | new_data ; |
描述
這是update_row方法。
old_data將保存前一行的記錄,而new_data將保存最新的數據。
如果使用了ORDER BY子句,伺服器能夠根據排序執行更新操作。不保證連續排序。
目前,new_data不會擁有已更新的auto_increament記錄,或已更新的時間戳字段。您可以通過下述方式(例如)完成該操作:if (table->timestamp_field_type & TIMESTAMP_AUTO_SET_ON_UPDATE) table->timestamp_field->set_time(); if (table->next_number_field && record == table->record[0]) update_auto_increment();
從sql_select.cc, sql_acl.cc, sql_update.cc和sql_insert.cc使用。
參數
old_data
new_data
返回值
無返回值。
用法
預設實施
{ return HA_ERR_WRONG_COMMAND; }
目的
為資料表新增新行。
概要
| virtual int write_row ( | buf); |
| byte * | buf ; |
描述
這是write_row方法。
write_row()用於插入行。目前,如果出現大量加載,不會給出任何extra()提示。buf是數據的字節數組,大小為table->s->reclength。
可以使用字段訊息從本地字節數組類型提取數據。例如:
for (Field **field=table->field ; *field ; field++) { ... }
BLOB必須特殊處理:
for (ptr= table->s->blob_field, end= ptr + table->s->blob_fields ; ptr != end ; ptr++)
{
char *data_ptr;
uint32 size= ((Field_blob*)table->field[*ptr])->get_length();
((Field_blob*)table->field[*ptr])->get_ptr(&data_ptr);
...
}
關於以字串形式提取所有數據的示範,請參見ha_tina.cc。在ha_berkeley.cc中,對於ha_berkeley自己的本地儲存類型,給出了一個通過「包裝功能」完整保存它的例子。
請參見update_row()關於auto_increments和時間戳的註釋。該情形也適用於write_row()。
從item_sum.cc、item_sum.cc、sql_acl.cc、sql_insert.cc、sql_insert.cc、sql_select.cc、sql_table.cc、sql_udf.cc、以及sql_update.cc使用。
參數
數據的buf字節數組
返回值
無返回值。
用法
預設實施
{ return HA_ERR_WRONG_COMMAND; }